Introduction to GPT Models
- ASHWIN CHAUHAN
- Nov 16, 2024
- 10 min read

Generative Pretrained Transformers (GPT) have revolutionized the field of natural language processing (NLP) and AI at large. Developed by OpenAI, GPT models are capable of generating coherent and contextually relevant text, translating languages, summarizing long documents, and performing a myriad of other language-related tasks.
These models have been trained on vast amounts of data from the internet, enabling them to learn the nuances and intricacies of human language. The ability of GPT models to generate human-like text has opened up new possibilities in AI applications, from chatbots and virtual assistants to content creation and beyond.
Breaking Down the Acronym: GPT
Understanding what GPT stands for is the first step toward grasping the capabilities and functioning of these models.
Generative
The term Generative signifies that these models are designed to generate new data. In the context of GPT, it means producing text that was not part of its original training data but is synthesized based on patterns learned during training.
Creativity and Originality: GPT models can create original sentences, paragraphs, and even entire articles that are coherent and contextually appropriate.
Applications: This generative capability is crucial for tasks like content creation, language translation, and conversational agents.
Pretrained
Pretrained indicates that the model has already undergone an extensive training phase on a large corpus of text before being deployed or fine-tuned for specific tasks.
Extensive Training: The model learns grammar, facts about the world, reasoning abilities, and some understanding of context from the vast data it was trained on.
Transfer Learning: Pretraining allows the model to apply its general understanding to specific tasks with less additional training data.
Fine-Tuning: After pretraining, the model can be fine-tuned on a smaller, task-specific dataset, enhancing its performance in particular areas.
Transformer
The Transformer is the core architecture that enables the model to process input data efficiently and effectively.
Innovation in NLP: Introduced in the paper "Attention is All You Need" by Vaswani et al., the transformer architecture addressed the limitations of previous models like recurrent neural networks (RNNs) and convolutional neural networks (CNNs).
Parallel Processing: Transformers allow for parallel processing of input data, significantly speeding up training and inference times.
Attention Mechanisms: Central to transformers is the attention mechanism, which lets the model focus on different parts of the input when generating each part of the output.
Overview of Transformers
Transformers are neural network architectures designed to handle sequential input data, making them ideal for language tasks where the order and context of words are crucial.
Sequential Data Handling: Unlike RNNs, which process data sequentially, transformers process all input tokens simultaneously, allowing for better handling of long-range dependencies.
Long-Range Dependencies: Transformers can capture relationships between words that are far apart in the text, improving understanding and coherence in generated language.
Efficiency: The ability to process data in parallel reduces the time required for training and inference.

Applications of Transformers
Transformers have a wide range of applications across various domains due to their versatility and powerful language understanding capabilities.
Language Translation
Original Purpose: Transformers were initially developed for machine translation tasks.
Functionality: They can translate text from one language to another by learning correspondences between languages.
Text Generation
Predictive Text: GPT models predict the next word in a sequence, enabling them to generate coherent and contextually appropriate text.
Content Creation: They can write articles, stories, poems, and even code snippets.
Image Generation
DALL·E and Midjourney: These tools use transformers to generate images from textual descriptions.
Cross-Modal Understanding: They bridge the gap between text and visual data, understanding descriptions to create corresponding images.
Speech Recognition and Synthesis
Transcription: Transformers can convert spoken language into written text.
Speech Generation: They can generate human-like speech from text inputs, useful in virtual assistants and accessibility tools.
Detailed Architecture of Transformers
Understanding the transformer model requires a deep dive into its components and how they work together to process and generate language.
Tokenization
Definition: Tokenization is the process of breaking down text into smaller units called tokens.
Types of Tokens:
Word Tokens: Individual words.
Sub word Tokens: Pieces of words, useful for handling rare or complex words.
Character Tokens: Individual characters, less common in transformers.
Purpose: Converts text into a format that the model can process numerically.
Embeddings
Concept: Embeddings are numerical representations of tokens in a continuous vector space.
High-Dimensional Space: Each token is mapped to a vector in a space with many dimensions (e.g., 768 dimensions in BERT).
Semantic Meaning: Tokens with similar meanings are located close to each other in this space.

Understanding Embeddings
Embeddings capture various linguistic properties and relationships:
Semantic Similarity: The distance between embeddings reflects how similar words are in meaning.
Syntactic Information: Embeddings can also capture grammatical relationships.
Analogies and Relationships: Mathematical operations on embeddings can reveal analogical relationships.
Examples:
Gender Analogy:
Mathematical Expression: king - man + woman ≈ queen
Interpretation: Adjusting for gender changes the embedding from male to female equivalents.
Plurality Direction:
Difference between cats and cat represents the concept of plurality.
This direction in embedding space can be applied to other singular-plural pairs.
Positional Encoding
Since transformers process all tokens simultaneously, they need a method to incorporate the sequential order of tokens.
Purpose
Sequence Information: Positional encoding provides information about the position of each token in the sequence.
Order Sensitivity: Helps the model understand the order of words, which is crucial for meaning in language.
Method
Sine and Cosine Functions: Positional encodings are generated using sine and cosine functions of different frequencies.
Unique Encoding for Each Position: Each position in the sequence has a unique encoding that is added to the token embedding.
Enabling Patterns: Allows the model to recognize patterns related to the positions of words.
Attention Mechanism
The attention mechanism is the heart of the transformer architecture, enabling the model to weigh the importance of different tokens when processing a sequence.
Self-Attention
Concept: Allows each token to consider other tokens in the sequence to build a richer representation.
Mechanism: Computes attention scores between tokens to determine how much one token should focus on another.
Benefits:
Contextual Understanding: Captures dependencies regardless of their distance in the sequence.
Parallelism: Enables simultaneous computation for all tokens.
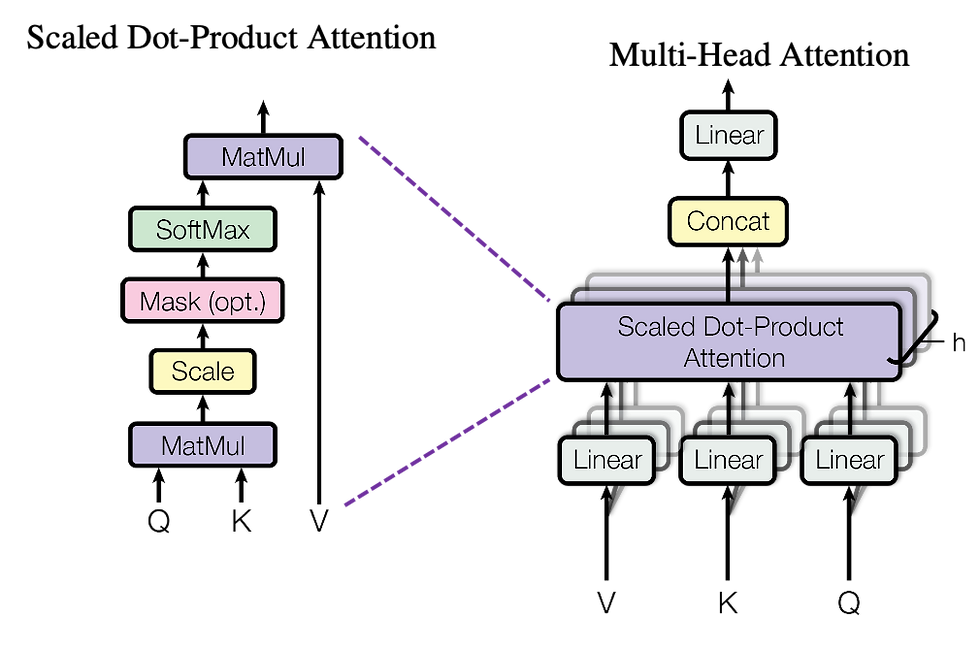
Calculations:
Queries (Q), Keys (K), and Values (V):
Each token generates a query, key, and value vector through learned linear transformations.
Attention Scores:
Compute the dot product between queries and keys to get raw attention scores.
Softmax Normalization:
Apply softmax to the scores to get weights that sum to 1.
Weighted Sum:
Multiply the weights by the value vectors to get the final representation.

Multi-Head Attention
Concept: Uses multiple attention mechanisms (heads) in parallel.
Purpose:
Capture Different Relationships: Each head can focus on different aspects of the relationships between tokens.
Increase Model Capacity: Improves the ability to model complex patterns.
Process:
Linear Projections: For each head, apply different linear transformations to obtain queries, keys, and values.
Parallel Attention Computation: Compute attention outputs for each head independently.
Concatenation: Concatenate the outputs of all heads.
Final Linear Layer: Apply a linear transformation to the concatenated output.
Feed-Forward Neural Networks
After the attention mechanism, each token's representation is further processed individually by a feed-forward neural network (FFN).
Purpose
Non-Linear Transformations: Applies additional transformations to capture complex patterns.
Token-Wise Processing: Operates independently on each token's representation.
Operation
Two Linear Layers:
The FFN consists of two linear transformations with a non-linear activation function (typically ReLU) in between.
Activation Function:
Introduces non-linearity, allowing the model to capture complex relationships.
Layer Normalization and Residual Connections
Layer Normalization
Purpose: Stabilizes and accelerates training by normalizing the inputs of each layer.
Function: Normalizes the activations to have a mean of zero and a variance of one.
Benefits:
Reduced Internal Covariate Shift: Helps maintain consistent distributions of activations throughout the network.
Residual Connections
Concept: Adds the input of a layer to its output.
Purpose:
Eases Training of Deep Networks: Mitigates the vanishing gradient problem.
Information Flow: Allows earlier representations to be reused in later layers.
Generating Output with Transformers
After processing the input through multiple layers of attention and feed-forward networks, the transformer model generates output, typically in the form of probabilities over the vocabulary.
Unembedding and SoftMax
Unembedding Matrix
Function: Maps the final hidden states back to the token vocabulary space.
Process:
Multiply the hidden states by the unembedding matrix.
The result is a vector of logits for each possible next token.
SoftMax Function
Purpose: Converts logits (unnormalized scores) into probabilities.
Characteristics:
Exponentiation: Applies the exponential function to each logit.
Normalization: Divides by the sum to ensure probabilities sum to 1.
Sampling and Temperature Control
Sampling
Process: Selecting the next token based on the probability distribution.
Methods:
Greedy Sampling: Choose the token with the highest probability.
Random Sampling: Sample tokens according to their probabilities.
Temperature Parameter
Purpose: Controls the randomness and creativity of the generated text.
Effect:
Low Temperature (<1):
Less Randomness: The model is more conservative, favoring high-probability tokens.
Predictable Output: Results in more coherent but potentially less creative text.
High Temperature (>1):
More Randomness: Increases the chance of selecting lower-probability tokens.
Creative Output: Can produce more diverse and imaginative text but may reduce coherence.
Examples:
Low Temperature Output:
"Once upon a time, there was a little girl who lived in a village near the forest."
High Temperature Output:
"Once upon a breeze, a curious shadow danced with the whispers of ancient trees.
Training Transformers
Training transformer models involves optimizing their parameters so that they perform well on the desired tasks.
Backpropagation and Gradient Descent
Backpropagation
Purpose: Calculates gradients of the loss function with respect to each parameter in the network.
Process:
Forward Pass: Compute the output and loss for a given input.
Backward Pass: Propagate the error backward through the network to compute gradients.
Gradient Descent
Optimization Algorithm: Uses the gradients to update the model's parameters.
Loss Function
Cross-Entropy Loss
Definition: Measures the difference between the predicted probability distribution and the true distribution.
Purpose: Encourages the model to assign high probabilities to the correct tokens.
Large-Scale Training
Datasets
Extensive Data: Transformers are trained on massive datasets containing diverse text from the internet (e.g., Common Crawl, Wikipedia).
Diversity: Exposure to various topics, writing styles, and languages enhances the model's generalization capabilities.
Iterations
Epochs: The model goes through the dataset multiple times.
Batch Training: Data is divided into batches to manage memory and computation.
Continual Adjustment: Parameters are continuously updated to minimize the loss.
Challenges
Overfitting: Risk of the model memorizing training data instead of learning general patterns.
Regularization Techniques:
Dropout: Randomly deactivating neurons during training.
Weight Decay: Penalizing large weights to prevent overfitting.
Limitations and Challenges
Despite their capabilities, transformers face certain limitations and challenges that researchers and practitioners must address.
Context Window Size
Fixed Length
Definition: Transformers have a maximum context length, often defined by the number of tokens they can process at once (e.g., 2048 tokens in GPT-3).
Limitation: The model cannot directly consider information beyond this window.
Implications
Long Documents: Difficulty in processing or generating texts longer than the context window.
Long-Term Dependencies: Challenges in capturing relationships between distant tokens outside the window.
Solutions
Hierarchical Models: Break down long texts into smaller chunks and model their interactions.
Memory Mechanisms: Incorporate external memory to store and retrieve information beyond the context window.
Computational Resources
Large Models
Size and Complexity: Models like GPT-3 have billions of parameters, requiring substantial computational power.
Training Time: Training can take weeks or months on specialized hardware.
Optimization Techniques
Model Parallelism: Distribute the model across multiple devices to handle larger architectures.
Data Parallelism: Split data across devices to speed up training.
Mixed-Precision Training: Use lower-precision arithmetic to reduce memory usage and increase speed.
Environmental Impact
Energy Consumption: Large models consume significant energy, raising concerns about environmental sustainability.
Efforts to Mitigate:
Efficient Algorithms: Develop algorithms that reduce computational requirements.
Green Energy: Use renewable energy sources for data centers.
Practical Usage of Transformers
Transformers have been adapted for practical applications, moving from theoretical models to tools that can be used in real-world scenarios.
From Prediction to Conversation
Autoregressive Generation
Concept: The model generates text one token at a time, each time conditioning on all previously generated tokens.
Process:
Input Prompt: The model takes an initial prompt.
Generation Loop: Repeats the process of predicting and sampling the next token.
Conversation Modeling
Dialogue Structure: Inputs are structured to simulate a conversation, including speaker tags like "User:" and "Assistant:".
Context Retention: The model keeps track of the conversation history within the context window.
Example:
User: How's the weather today? Assistant: The weather is sunny with a high of 75 degrees. User: Should I bring an umbrella? Assistant: It doesn't look like rain, so you probably won't need one.
Fine-Tuning for Specific Tasks
Adaptation
Process: The pretrained model is further trained on a task-specific dataset.
Benefits:
Improved Performance: Enhances the model's ability on specific tasks.
Reduced Data Requirement: Requires less data than training from scratch.
Tasks
Question Answering: Answering questions based on given context.
Summarization: Condensing long documents into shorter summaries.
Sentiment Analysis: Determining the sentiment expressed in text.
Reinforcement Learning with Human Feedback (RLHF)
Purpose: Aligns the model's outputs with human preferences and ethical guidelines.
Process:
Human Feedback: Humans evaluate model outputs.
Policy Optimization: The model adjusts its parameters to produce more preferred outputs.
Benefits:
Ethical Alignment: Reduces harmful or biased outputs.
Improved User Experience: Produces responses that are more helpful and appropriate.
Conclusion
Transformers have fundamentally transformed the landscape of AI and natural language processing. By efficiently modeling long-range dependencies and capturing complex patterns in data, they enable the creation of advanced language models capable of generating human-like text and understanding context at a deep level.
Understanding the inner workings of transformers—from tokenization and embeddings to attention mechanisms and output generation—provides valuable insights into how models like GPT-3 and ChatGPT function. This knowledge is essential for researchers, practitioners, and enthusiasts looking to harness the power of transformers in various applications.
As we continue to explore and develop these models, it is crucial to address their limitations and consider the ethical implications of their use. The future of transformers holds immense potential, and with responsible development, they can significantly contribute to advancements across multiple fields.
Next Steps
For those interested in delving deeper into the world of transformers, several avenues offer rich exploration opportunities.
Attention Mechanism Details
Queries, Keys, and Values: Understanding the mathematical foundations and implementation details.
Scaling Factors: Exploring why scaling by dk\sqrt{d_k}dk is necessary.
Visualization: Analyzing attention weights to interpret model focus.
Multi-Head Attention
Diversity of Heads: Investigating how different heads capture various aspects of language.
Head Importance: Determining the contribution of each head to the model's performance.
Head Pruning: Experimenting with reducing the number of heads for efficiency.
Transformers Beyond NLP
Computer Vision: Applying transformer architectures to image recognition and generation (e.g., Vision Transformers).
Reinforcement Learning: Using transformers to model sequences of actions and states.
Time-Series Analysis: Employing transformers for forecasting and anomaly detection.
Ethical Considerations
Bias and Fairness: Identifying and mitigating biases present in training data and model outputs.
Responsible AI Practices: Establishing guidelines for ethical use and deployment.
Transparency and Explainability: Enhancing the interpretability of transformer models.



Comments